
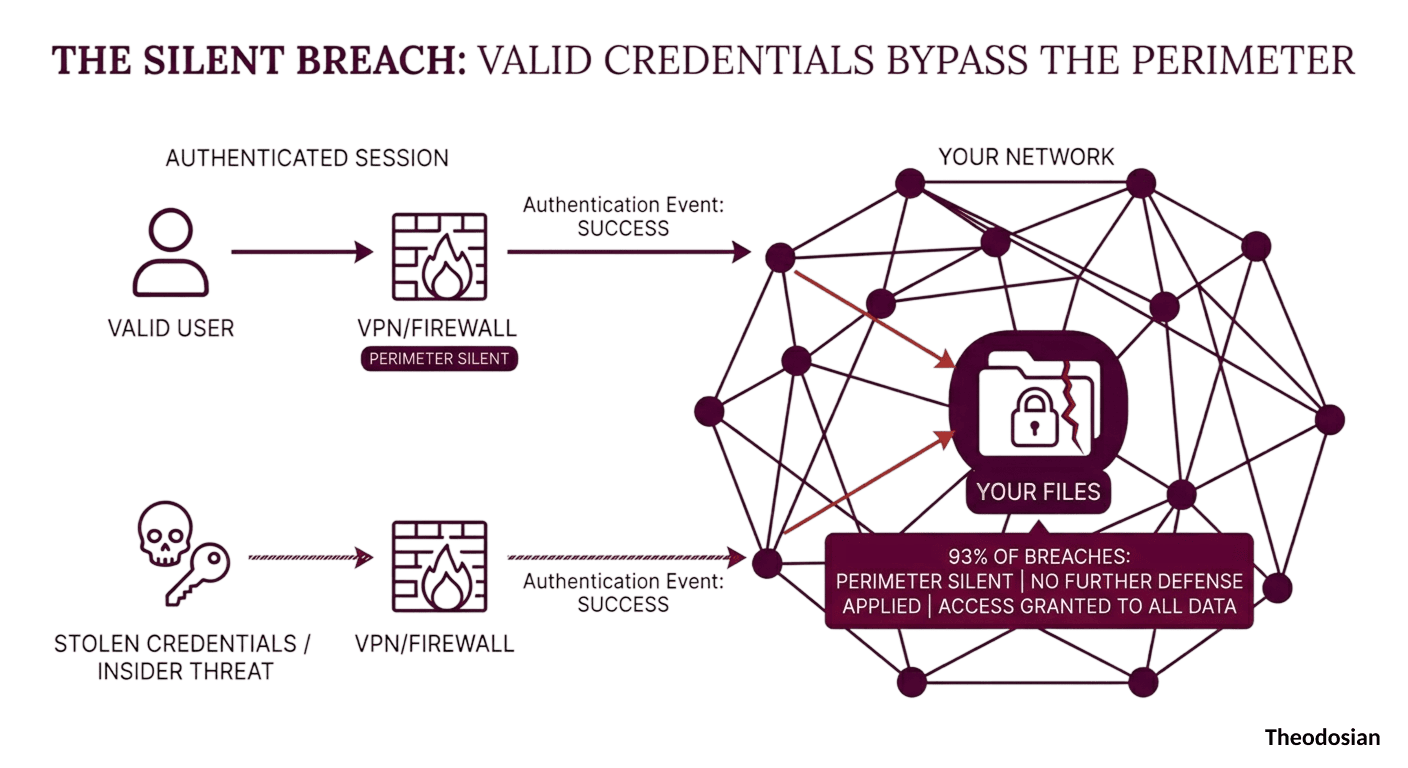
According to the CyberArk 2024 Identity Security Threat Landscape Report, 93% of breaches involve stolen credentials or insider threats. The Verizon 2025 DBIR puts credential abuse as the leading attack vector — present in 22% of all breaches and 88% of web application attacks.
Read those numbers carefully. In 93% of breach scenarios, the attacker is not breaking through the perimeter; they are walking through it, and the credential is valid. The authentication event succeeds, the access is granted, and from that moment, the perimeter — the architecture that most security budgets are built around — has no further role to play.
This is a huge architectural problem. Perimeter security was designed to validate access events; it was never designed to govern what happens to data after those events occur.
Data-centric security is the architectural response to that gap. Not a replacement for perimeter controls, but an extension of protection to the layer where protection actually runs out.
🔌 See How Data-Centric Security Architecture Works
Theodosian applies FIPS 140-3 validated per-file encryption and contextual access controls that travel with the file — through email, contractor devices, and offline environments.
Why is Perimeter Security Failing Against Modern Cyber Threats?
The perimeter security model is built on a specific assumption: hostile exterior, trusted interior. You invest in walls — firewalls, VPNs, network segmentation — and you control the gates. Anyone inside the walls is assumed to be authorized.
That assumption fails in three recurring scenarios that collectively account for the overwhelming majority of data loss events:
- Credential Compromise: A valid credential, however obtained, grants interior access. Phishing, infostealer malware, and credential stuffing — the method is irrelevant to the perimeter. The credential passes the gate check. The attacker is inside.
- Insider Threat: Malicious or negligent insiders are already inside by definition. Perimeter controls have no mechanism to distinguish between an authorized user performing authorized tasks and an authorized user exfiltrating data — because both look identical at the access event layer.
- Authorized Data Movement: Files legitimately downloaded by authorized users for legitimate purposes — contractor access, remote work, email collaboration — leave the perimeter completely. From the moment of download, the file is outside every control the perimeter architecture can enforce.
The 93% figure is the mathematical consequence of these three failure modes. Perimeter security is fully functional in those breaches. It just wasn't designed to stop what happened next.
What Is Object-Level Authorization, and How Does It Protect Data?
Most access control systems operate at the container level: directory permissions, folder access, and role-based access to systems and applications. The unit of control is the environment — who can reach the folder, who can log into the application, and who can access the network segment.
Object-level authorization moves the unit of control to the individual file. Every open attempt on every governed document triggers a real-time evaluation against a contextual policy: is this identity authorized, on this device, in this location, on this network, at this time? Not a permission inherited from the folder. A live decision on this specific file, at this specific moment.
The architectural distinction matters in practice:
- A folder permission persists until manually changed. An object-level contextual check is evaluated fresh on every access attempt against the current device posture, current location, current behavior, and more.
- A folder permission applies uniformly to everything inside it. Object-level authorization can apply different policies to different files in the same repository — based on sensitivity, classification, or subject matter.
- A folder permission is binary: access or no access to the container. Object-level authorization evaluates six dimensions simultaneously: identity/role (via IdP, RBAC/ABAC), device compliance, geographic restriction, network and IP context, time-based parameters, and behavioral signals.
When the contextual check fails — because the user's device is non-compliant, their location is outside policy, their access has expired, or their behavior has deviated from baseline — the file doesn't open. Not a permission error on the folder, a denied access decision on the specific file, at the specific moment of the attempt.
What Are the Risks of Using a Centralized Rights Server for Encryption?
Traditional IRM and rights management architectures apply object-level controls using a centralized rights server: a central system that holds the policies, manages the keys, and validates access requests before authorizing file decryption.
This architecture addresses the container vs. object limitation. But it introduces a different structural vulnerability: the central rights server becomes a single point of failure and a concentrated high-value target. Compromising the rights server compromises governance over every file in the protected inventory simultaneously.
More critically, in a centralized key management model, the organization's ability to maintain object-level authorization depends entirely on the availability and integrity of the central server. Offline access, latency, and operational continuity all become dependencies on a single system that holds the keys to your entire governed file set.
The architectural alternative is decentralized, zero-knowledge key management. Each file carries its own unique encryption key. There is no master key, no central key store, no single system whose compromise undermines the entire governed inventory. The organization issuing the policy never holds the decryption keys — and neither does the infrastructure provider. Authorization decisions are made at the point of access, not routed through a central validation server.
This is not a marginal architectural distinction. It is the difference between a security model that creates a new high-value honeypot and one that eliminates the honeypot entirely.
Does Zero Trust Architecture Protect Data Once It Leaves the Network?
Zero Trust has become the dominant framework for identity and network security — and correctly so. Continuous verification, device posture checking, microsegmentation, and least-privilege access controls have materially raised the cost of lateral movement for attackers who do achieve initial access.
But Zero Trust's operating scope is the access event and the network environment. The Federal Zero Trust Data Security Guide (October 2024, revised May 2025) identifies the data pillar as explicitly the least mature in most federal Zero Trust implementations. NIST SP 800-207 acknowledges directly that Zero Trust Architecture does not protect data that has already left the system.
Once a file is downloaded to a contractor's laptop, forwarded as an email attachment, or synced to a personal cloud account, Zero Trust has no further visibility or enforcement capability. The access event was verified, and the file is on its own.
Data-centric security doesn't replace Zero Trust. It extends protection to the layer Zero Trust was never designed to reach — the file itself, in every environment it travels through, on every device it reaches, evaluated on every open attempt against the current context. The two architectures are complementary: Zero Trust controls the gate, data-centric security governs what goes through it.
The Three Requirements of a Real Data-Centric Architecture
Not all "data-centric" security products deliver the same architectural guarantees. Three requirements separate genuine object-level protection from folder-permission security with a new label:
- FIPS 140-3 Validated Per-File Encryption: Each file must carry its own encryption, implemented by a cryptographic module validated under the NIST Cryptographic Module Validation Program. FIPS 140-3 is the current standard. AES-256 implemented by an unvalidated module does not meet this requirement. The validation must be at the module level, not the algorithm level, and the certificate must appear on the NIST CMVP active list.
- Zero-Knowledge, Decentralized Key Management: The vendor must not hold decryption keys. There must be no master key, no central key store, and no single system whose compromise creates access to the governed file inventory. Each file's key must be unique, and key operations must be decentralized — eliminating the centralized rights server vulnerability described above.
- Contextual Access Evaluation on Every Open Attempt: Protection must be continuous, not one-time. Every file open triggers a live evaluation against current identity, device compliance, geographic location, network context, time parameters, and behavioral signals. This is not a cached authorization decision from login. It is a fresh contextual decision on this specific file, at this specific moment — wherever the file is, on whatever device, in whatever environment.
An architecture that meets all three requirements is genuinely data-centric. One that meets two of the three has a gap, and that gap is where 93% of breaches currently live.
What Does "Persistent Protection" Mean?
The word "persistent" is doing a lot of work in data-centric security marketing. Here is the concrete definition: a file is persistently protected if its access controls remain in force regardless of where the file is stored, what application is used to open it, what network it's on, and whether the original access environment still exists.
Practically, persistent protection means:
- A design file emailed to a subcontractor is subject to the same contextual access policy as when it sat in your SharePoint library.
- A proposal downloaded by a remote employee is evaluated against the current device posture and location policy when they attempt to open it offline.
- A CUI document that a former contractor downloaded before offboarding cannot be opened after their access context is updated — the contextual check fails, access is denied, regardless of how many copies exist on how many devices.
The protection isn't a label on the file. It's a live policy evaluation baked into every open attempt — running continuously, everywhere the file travels.
🔎 See How Data-Centric Security Maps to Your Environment
Theodosian's 14-day pilot scopes to a defined file population — CUI repository, ITAR design library, or contractor project folder — and demonstrates per-file contextual access controls against your actual infrastructure. No migration or disruption.
FAQ: Data-Centric Security Architecture
Is data-centric security the same as DRM or IRM?
No. Traditional Digital Rights Management (DRM) and Information Rights Management (IRM) apply policy controls to files — but typically through centralized rights servers and static policy assignments. Data-centric security, as an architectural category, requires per-file encryption with decentralized key management and contextual access evaluation on every open attempt. IRM can be a component of a data-centric architecture, but centralized IRM implementations lack the zero-knowledge key management and continuous contextual evaluation that define genuine object-level protection.
How does data-centric security handle ITAR and CMMC compliance simultaneously?
CMMC's SC.3.177 requires FIPS-validated encryption. ITAR requires that controlled technical data maintain access controls wherever it exists — including on contractor devices and in collaborative environments. A data-centric architecture that applies per-file FIPS 140-3 validated encryption with contextual access controls satisfies both requirements with a single implementation. The file carries its compliance posture with it — into the subcontractor environment, onto the contractor's device, and through every transmission. See ITAR compliance guidance and CMMC solutions.
What's the difference between data-centric security and Zero Trust?
Zero Trust governs access events and network environments — who can connect, from what device, to what resource. Data-centric security governs the file itself — what happens to data after a legitimate access event occurs. They address different threat surfaces and are architecturally complementary. The Federal Zero Trust Data Security Guide explicitly identifies the data pillar as a separate requirement from identity, device, network, and application controls.
Does data-centric security work without an internet connection?
A correctly implemented data-centric architecture evaluates access policy at the point of the open attempt. For offline scenarios, access decisions are made against cached policy parameters — device compliance state, pre-authorized time windows, and offline access grants set by the policy owner. Files that require real-time contextual validation (location, network, live behavioral signals) will deny access in offline environments where those signals can't be evaluated. This is configurable based on sensitivity classification and operational requirements.
Does implementing data-centric security require replacing existing infrastructure?
No. Per-file encryption and contextual access controls integrate at the data layer, not the platform layer. Existing cloud storage, email infrastructure, endpoint tooling, and identity providers remain in place. Files are protected through a classification workflow applied to existing repositories. End users open governed files through the same applications they use today. The integration is additive, not a platform replacement.