
The audit started routinely. A Tier 2 defense contractor submitted its annual CMMC 2.0 assessment. Three days in, the auditor asked a simple question: "Where is your Controlled Unclassified Information (CUI) stored?"
The security team began listing locations: the main file server, a SharePoint instance, two OneDrive accounts, a Box folder maintained by a contractor, an encrypted external drive in the CFO's desk, and a cloud backup that IT wasn't aware of. By the end of the audit, they had found CUI spread across 14 different storage locations, some encrypted, some not, none consistently governed. Nobody could tell the auditor who had accessed the data last month. Nobody could prove that only cleared personnel had seen it.
The auditor's finding was simple: non-compliant. The security team hadn't suffered a breach. They hadn't lost a file. They had simply lost track of where their data lived.
This is data sprawl. And it's the compliance risk that nobody is auditing, until they are.
What Is Data Sprawl?
Data sprawl is the uncontrolled spread of organizational data across storage systems, endpoints, cloud environments, and collaboration tools. It is not a failure of data storage; it is a failure of data governance architecture.
The distinction matters. A company can have well-organized storage and still experience data sprawl. A CISO can invest in cloud infrastructure, backup systems, and disaster recovery. None of that solves the problem if data governance doesn't travel with the data.
Here is the structural reality: 70 to 90% of organizational data is unstructured (reported by industry leaders IDC and Gartner) — documents, spreadsheets, emails, presentations, design files, technical drawings. Most of it is ungoverned. Most of it is not in your asset inventory. Most of it is not covered by your data loss prevention (DLP) policy because DLP was designed for network perimeters, not for data that has already left the perimeter.
The moment an employee saves a file to their personal OneDrive, copies it to a personal Google Drive, forwards it in Slack, or feeds it into an AI assistant, your data governance becomes disconnected from your data. You have lost situational awareness, and without situational awareness, you cannot audit. Without audit trails, you cannot comply.
This is not negligence. This is the unavoidable outcome of building security on a perimeter model in an era when data routinely leaves the perimeter.
🛡️ See the End of Data Sprawl in Action!
If 90% of your data is unstructured and outside your asset inventory, you can't protect it with a firewall. Theodosian embeds governance directly into the file, making storage location irrelevant to your compliance.
How Data Sprawl Happens in Modern Defense Organizations
Data sprawl is not random; it follows predictable patterns. Understanding where it originates helps explain why traditional controls miss it.
Remote Work Architecture: When employees work from home, they create local copies of sensitive files. Some are synced to personal cloud storage, some are saved to USB drives, and some remain on the laptop. The file was created in a governed environment, but the copy was not.
Cloud Migration Without Consolidation: Organizations migrate to Microsoft 365, then add Google Workspace for collaborative teams, then add Slack, then add Box for specific departments. Each system mirrors the same data. Each has different access controls, different retention policies, and different audit capabilities. The data is technically "cloud-based," but it is also exponentially more fragmented.
Shadow AI: Employees use ChatGPT, Claude, Gemini, and other generative AI tools to draft documents, analyze spreadsheets, and research technical problems. Sensitive documents are fed into these systems, sometimes deliberately, sometimes carelessly. The AI tool creates a copy. That copy is stored on the vendor's servers, likely outside your compliance boundary, and almost certainly outside your audit trail.
Merger and Acquisition Integration: When a company acquires another, inherited data environments often run in parallel with established systems for months or years. The acquired organization has its own file servers, its own cloud subscriptions, its own governance baselines — which may be incompatible with the parent company's policies.
Collaboration Tool Proliferation: Microsoft Teams, Slack, Zoom, and email clients all create ungoverned repositories. A file shared in Teams is copied to Teams' servers. The same file shared in Slack is copied to Slack's servers. The audit trail is fragmented across separate systems, each with different logging capabilities.
None of these patterns represents a breach. They represent the normal operation of modern work. This is why data sprawl is not a security incident waiting to happen. It is a compliance failure already happening.
The Compliance Cost of Data Sprawl
For CISOs at Tier 1 and Tier 2 defense subcontractors, data sprawl creates direct compliance exposure under every major framework.
CMMC 2.0 requires identification, control, and auditability of CUI. The requirement is not conditional on whether the data is at risk of breach. It is conditional on whether you can prove you know where it is and who has accessed it. Data sprawl makes this structurally impossible. An auditor will not accept "we don't know" as an answer.
ITAR (International Traffic in Arms Regulations) requires controls over technical data related to defense articles. The location of ITAR-controlled data is itself a compliance question. If your technical drawings are stored in an unsanctioned cloud location, you have potentially violated ITAR — even if the data is encrypted and even if access is restricted.
EAR (Export Administration Regulations) follows the same logic. EAR-controlled commodities and technical data must be controlled and accounted for. Data sprawl creates uncontrolled locations. Uncontrolled locations are a regulatory exposure.
HIPAA, SOX, and GLBA all require audit trails and demonstrable controls over sensitive data. If data exists in locations you cannot audit, you cannot prove compliance.
The critical point: You can fail a compliance audit without suffering a breach. You can fail because you cannot account for where your data is. Auditors do not award passes for "we tried our best." They issue findings.
For a Tier 2 subcontractor, a non-compliance finding can trigger contract suspension. For a public company, it creates regulatory exposure. For any organization, it creates liability.
Why Traditional Security Tools Miss It
Organizations typically respond to data sprawl by purchasing additional security tools: enhanced DLP, Cloud Access Security Brokers (CASB), Security Information and Event Management (SIEM), and Security Orchestration, Automation and Response (SOAR) platforms.
These tools have a shared limitation: they were designed for perimeter security. They work well inside the perimeter. They fail when the data leaves it.
DLP systems monitor data in motion, when it is being sent to external email addresses, uploaded to cloud storage, or transferred to USB drives. DLP is effective at detecting exfiltration. It is not effective at governing data that is already exfiltrated. A file that was legitimately copied to OneDrive six months ago is not a DLP alert. It is a compliance liability.
CASB solutions monitor usage of sanctioned cloud applications. They can see that an employee uploaded a file to Salesforce or SharePoint. They cannot see what the employee did in unsanctioned apps, personal accounts, or consumer AI tools. Shadow AI, by definition, operates outside the CASB scope.
SIEM and SOAR platforms collect and analyze access logs from connected systems. They are powerful tools for detecting intrusion patterns, lateral movement, and exfiltration events. But they only log what they are connected to. A file opened from a personal Dropbox account generates no SIEM alert. The access event happened outside the governed infrastructure.
The core architectural problem: All of these tools assume data stays inside the perimeter. Their alerting rules, their retention policies, and their audit capabilities are built on that assumption. Data sprawl violates the assumption. The tools become irrelevant.
This is not a tool problem; it’s an architecture problem. When your security model is perimeter-centric, data sprawl is a structural blind spot.
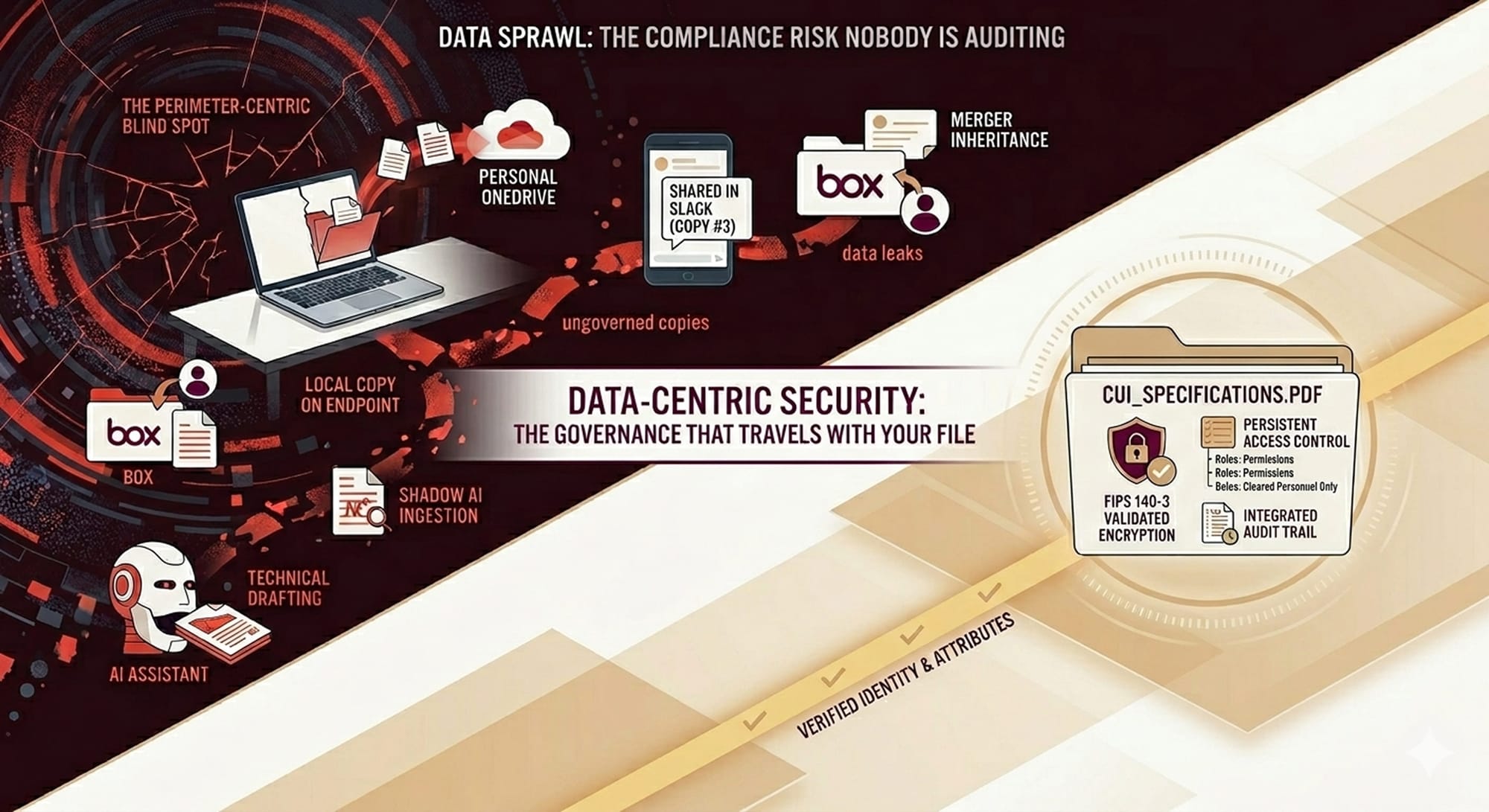
What a Data Sprawl Audit Actually Reveals
Most organizations, when they conduct their first comprehensive data location audit, discover they have been drastically underestimating the scope of their data sprawl.
According to benchmarks from IDC and Gartner on the growth of 'Shadow Data,' the typical finding is 3 to 5 times more storage locations than IT has on inventory. This includes rogue cloud subscriptions, legacy systems running in data centers, external drives, personal accounts synced to work devices, and archived systems that were never formally decommissioned.
Within those locations, audits typically reveal:
- Ungoverned copies of regulated data (CUI, PHI, ITAR technical specifications, financial records)
- Files created years ago, no longer actively used, with no clear retention owner
- Access permissions that are overly broad or outdated
- Encryption inconsistency — some files encrypted, others not, often determined by accident rather than policy
- Backup copies that bypass primary governance policies
- Contractor and vendor accounts with standing access to data they no longer need
The audit itself is not the solution; it is the starting point. The audit reveals the problem; fixing it requires a different approach.
Fixing Data Sprawl Without Stopping the Business
Organizations cannot solve data sprawl by restricting where employees work or how they collaborate. The modern workplace requires flexibility. Remote work, cloud tools, and AI integration are not luxuries; they are operational necessities.
The solution is not to prevent data from being copied or moved. The solution is to ensure that governance travels with the data, wherever it goes.
Persistent encryption: Per-file encryption using FIPS 140-3 validated algorithms (AES-256) means the file remains protected regardless of where it is stored or how many times it is copied. Encryption is not a property of the storage system; it is a property of the file itself.
Access controls at the file level: Authorization checks happen when the file is opened, not at the network edge. This means a file can be accessed from a sanctioned system, a personal device, a remote location, or a cloud application, and the access control is enforced consistently. A user who lacks clearance cannot open the file, regardless of where the file is stored or what account they are using.
Audit trails that travel with the data: Every access event; who opened the file, where, when, from which device, is logged and retained. The audit trail is not dependent on a specific SIEM connection or logging infrastructure. It is intrinsic to the file.
This is data-centric security. The file itself is the control point. The file carries its own governance with it. The file knows its classification, enforces its own access controls, maintains its own encryption, and logs its own access history.
When your controls are embedded in the data, data sprawl stops being a compliance liability. It becomes a non-issue. Data can be copied, shared, moved, and accessed from any location, and governance is maintained.
Ending Data Sprawl with Data-Centric Architecture
The real problem with data sprawl is not that auditors are finding it. It is that organizations are building their security architectures on a foundation that cannot accommodate modern work.
Perimeter security was designed for a world where data stayed inside the network. Data lived on servers you owned, in locations you controlled, connected to logging infrastructure you managed. That world does not exist anymore.
Modern organizations need a security architecture that does not depend on the perimeter. They need controls that travel with the data. They need governance that is intrinsic to the file, not imposed by a system the file happens to be stored on.
This is not a tool problem, and it's also not an audit problem; it's an architecture problem. When your controls live at the file level, data sprawl is no longer a compliance liability. It becomes operationally irrelevant.
The audit will still happen. But instead of discovering 14 ungoverned storage locations, the auditor will discover that every file, regardless of where it is stored, carries its classification, encryption, access controls, and audit trail with it. That is compliance.
🤖 Stop Shadow AI from Breaking Your Compliance!
Generative AI is the new frontier of data sprawl. Every prompt and uploaded document creates a copy outside your perimeter. Use our checklist to identify your "blind spots" before your next audit.
FAQs: Compliance Risk of Data Sprawl
What is the difference between data sprawl and shadow IT?
Shadow IT refers to unapproved applications and infrastructure that operate outside IT governance, employees using personal cloud accounts, installing unapproved software, or setting up parallel systems. Data sprawl is what happens when authorized and unauthorized systems accumulate without coordinated governance. A shadow AI tool is shadow IT. The files fed into it create data sprawl. Data sprawl can occur within sanctioned systems if governance is not coordinated across them.
How does data sprawl affect CMMC 2.0 compliance?
CMMC 2.0 requires identification and control of CUI. Auditors will ask you to prove that you know where all CUI is stored, who has accessed it, and when. If CUI exists in locations you cannot account for, or if your audit trail is fragmented across multiple systems, you will receive a non-compliance finding. Data sprawl makes this requirement structurally impossible to satisfy.
Can DLP tools fix data sprawl?
DLP tools are effective at preventing data exfiltration in real-time. They cannot govern data that has already been exfiltrated or copied to unsanctioned locations. A DLP alert tells you that a user attempted to send a file to an external email. It does not help you govern a file that already exists in that user's personal OneDrive. DLP is part of a defense-in-depth strategy, but it is not a solution to data sprawl.
What is the first step to getting data sprawl under control?
Visibility. Conduct an inventory of all storage locations where organizational data currently exists: cloud storage, endpoints, backup systems, vendor accounts, and archived systems. Map which data types (regulated or sensitive) exist in which locations. This audit will likely reveal data sprawl you were not aware of. Once you have visibility, you can design a governance approach. This might include data consolidation (moving everything to governed systems) or persistent governance (embedding controls in the data itself so location becomes irrelevant).